An AI Bubble is a human data problem
Precursor excerpt from "To Build an RL Envs and Human Data Startup"

The intended audience of this preview piece are human data companies, who have scaled human-QA processes that don’t produce realistic data for unverifiable domains, and entrenched cultures that prioritize volume over quality.
As always, reach out via my personal website with questions and corrections.
Good Data
Knowing what data is intrinsically valuable requires a good understanding of two things -
Understanding the macro view of where research dollars are being invested and
Understanding the shape of data that best aligns for the current stage of model training
Ironically - being a researcher yourself and training models yourself will naturally lend to expertise in these two areas. Which indicates, at a baseline, where you should start learning if you’re completely unfamiliar with everything here.
When many think about data, they default to thinking about “state-based” data. While state-based data with labels is quite useful for pre-training, it still falls in the outdated 2023 “next-token prediction” assumptions about how LLMs are predominantly trained. For modalities where pre-training data is abundant, state-based data is still quite valuable, but for modalities where post-training via rewards/trajectories in action spaces/RL envs is necessary to hill climb models to an economically valuable state, you need “process-based data.”
State-based data: static data that is rife with personal details, and the often the remnants of reasoning based workflows. These often represent user inputs, user details, and packaged user inputs for usage in software applications, as well as work outputs used as verification end-states.
Process-based data: trajectories, envs, rubrics, and semantic language defining reasoning-based workflows. These are PDFs a manager leaves to an intern to describe what they have to do (goals and tools used to accomplish the goals). These are unstructured reasoning traces detailing a possible reward rubric for that task. These are high fidelity documentations of the reasoning traces a white collar worker has in moving data - without much care as to the actual literal “state” based details of the data itself. This is why, via synthetic data anonymization, proper curation of this data type should avoid most GDPR-like privacy infringements.
From a thematic sense, good data is most immediately valuable when it is most easily usable to hillclimb a model on a metric that people care about. These include, but are not limited to:
Macro investment in work automation for a certain white collar domain (as of Jan 2026, finance/healthcare/law)
Data, envs, and benchmarks that are simply “one step” above model capabilities - most models fail on it but can easily feasibly hillclimb with what’s available in researcher toolkits
Data that matches modality sophistication. In audio, we have still a large dearth of pre-training data for some domains (which can be fulfilled with million hour english datasets), but also demand for post-training datasets that are as small as nicely labelled datasets of niche languages in goal-oriented settings.
Mechanically, data is also valuable when it can be formatted into a shape for RL that makes complex tasks deterministically verifiable. In other words, we’d like to optimize for data and associated data products that increasingly bound asymmetry of verification by as objective means as possible. To quote Jason Wei:
“Verifier’s law” states that the ease of training AI to solve a task is proportional to how verifiable the task is. All tasks that are possible to solve and easy to verify will be solved by AI. The ability to train AI to solve a task is proportional to whether the task has the following properties:
Objective truth: everyone agrees what good solutions are
Fast to verify: any given solution can be verified in a few seconds
Scalable to verify: many solutions can be verified simultaneously
Low noise: verification is as tightly correlated to the solution quality as possible
Continuous reward: it’s easy to rank the goodness of many solutions for a single problem
In terms of economic buying, here are three concepts of verification that matter today to build systematic processes for identifying economically valuable things to verify:
Asymmetry of verification - how difficult is it to break a task into a series of verifiable steps?
Veracity of verification - how consensus is the definition of verification?
Proliferation of verification - how often are we supplied real world examples of verification?
Domains with low veracity and proliferation of verification require ever more frequent data access pipelines to counteract those difficulties. You can imagine how Goodhart’s Law compounds in opportunities for reward hacking in lower veracity/proliferation of verification domains.
I write about how all of these conditions make coding the first mature AI app layer market:

Verification in economically valuable settings usually occurs in envs where we give models the tools to accomplish these tasks. What is an RL env? Colloquially speaking - a piece of software (usually dockerized) where we can plug and play a model, accessing various tools pre-built in the software and integrated, to complete various unit tests. Simply put:
CRUD Tool calls
Low level reasoning tool calls
VMs and computer use
Some lab buyers have their own environments and request vendors to curate their own packaged docker containers containing “envs” that mostly consist of tool calls, eval rubrics, and reward/verification functions. In this way, they abstract away env creation from the vendor, and ask the vendor to provide reasoning trace data to fit the labs’ specification. At this point of time - many labs have built their own versions of Antikythera mechanisms that they simply need raw data inputs for.
Some tool calls are not APIs - but they need to be as deterministic as possible. As you can imagine (from the above 3), the last 2 are the most difficult to be opinionated about to make as deterministic as possible. Good design of the last 2 (that, importantly, adheres to realism, or real economically valuable work) in deterministic fashion is the entire art of overcoming asymmetry of verification. Veracity and Proliferation of verification, then, are factors that highly influence design choices around RL env design and how often RL envs need to be updated or changed.
But as AI app layer use cases mature, envs and tasks also mature in complexity. Consider the following adapations:
“Multi-environment” tasks where it becomes unfeasible to create one env with 100 tools, and instead more realistic and feasible to create 10 envs with 10 tools each that a single agent must navigate. This actually aligns quite well with some real world examples where certain tasks must be completed first (in their own quite defined and complicated environments) to get the right reasoned approach for the next step.
Reasoning about using dynamic tools. While we prefer to keep all of our tools’ outputs as deterministic as possible, see what happens when you give your agents’ access to a SOTA foundation model call as a search function in an RL environment. Theoretically, they could learn to use AI tools better than us, if provided training on all the hyperparameters that go into foundation model calls to make them relatively deterministic, especially if the models are static (and probably hosted locally) to make them deterministic.
Whereas we expect agents to spin up and orchestrate sub agents with their own complicated trajectories. This is increasingly the case not even for modeling best practices uses, but also for latency as long horizon tasks naturally compound in time to complete. Latency itself as a reward function adds another layer of complexity.
If a base model like Opus 4.5 gets better, you can naturally expect the lengths of substeps to grow in what you can consider “deterministic.” For example, Opus 4.5 can reliably one shot bespoke coding tool execution for some low level data analysis tasks, which will only extend farther as N-1 models get better and latency/cost improves. Perhaps MoE should be baked into base foundation models as a research direction.
A permutation of the above is especially common in coding, where Opus 4.5 has long been able to one-shot many common software development tasks given the correct tool calling integrations and context.
Throughout this discussion - you’ll notice something interesting. YC’s mantra is “build something people want,” which is not what necessarily happens. That’s because the buyer dynamics in that of labs look a lot like mini-experiments consisting of Sam A and a bunch of amazing fundraisers giving exceptionally talented researchers money to go tell them to explore a bunch of research directions. Simply put - they do not know what they want and are amenable to being taught/persuaded - thus seeking thought partners for discovering and supplying the right shape of data to advance model capability in some random direction. On the other hand, OTS (off the shelf) dataset diverge more clearly as a buyer priority - whereas labs have already pre-determined the shape of data they find valuable.
The prior examples are to convey that researchers are not consistent as a buyer class, across labs, and sometimes even amongst teams in labs. A lot of this stems from unsophistication around data quality, individual-to-individual relationships, and frankly much ability from the buyer side to pitch poor quality data as high quality without much external audit scrutiny.
I propose a separate classification rubric for how you should think about grades of data, accordingly to how they’re produced and QA’ed:
Type 1 Data: Data in its purest form as to avoid reward shaping by non-domain experts. The theoretical form of this data looks like a combination of observation mechanisms of white collar work (as to border session replays) and inferring reward signals from observed behavior. The best form of this data finds unique bespoke mechanisms to infer intent from unobvious user behavior, or otherwise mechanisms to collect semantic reward commentary from experts in a way that doesn’t degrade UI/UX too much.
You’ll notice that the unique bespoke mechanisms that constitute inferring user intent can easily be the software 2.0 collaboration tooling that white collar work is currently done on. In coding - it is GitHub (which provides the highest fidelity intent to reasoning step examples via github commit messages and ticket resolutions)
Session replay data, as AI app layer use cases advance, constitute the purest form of raw trajectory data that researchers could want, down to the keystroke/kernel level. We already clearly see this in the most advanced AI app layer modality (coding) and would see it more in other domains if researchers had the same level of domain expertise in coding as in other white collar tasks.
Type 2 Data: Known as “contrived data,” whose collection mechanisms involve hiring some amount of domain experts, corralling them in ways to produce data in “arbitrary” realistic settings, and collecting scattered and varied data outputs and formatting them into model actionable formats.
On the issues of veracity and proliferation of verification, you’ll generally find that the farther the contracted experts are away from “actual work,” data quality outputs in particularly low veracity and proliferation verification domains tend to suffer. Even if you could ignore the other scaling issues with this operational structure, you’ll inevitably run into problems related to scaling large amounts of humans creating standardized data products.
Scaling Type 2 Data effectively requires strong QA automation pipelines. In AI-presenting companies (like most human data companies), asking talented engineers to build actually good QA automation pipelines is like asking backend devs to structure divs and do front end work on your homepage. Engineering-focused QA automation pipeline, which understands an extremely strong ML baseline, is oft forsaken in many human data companies. The most common culprit for engineering work that is supposed to be devoted to this category is instead used in forward deployed RL env creation for short term revenue maximization.
To put it a different way, can you really expect data produced via scaled Type 2 processes with almost wholly non-domain expert human based QA interference to accurately slice workflows into verifiable pieces or catch learned, nuanced signals for human preferences?
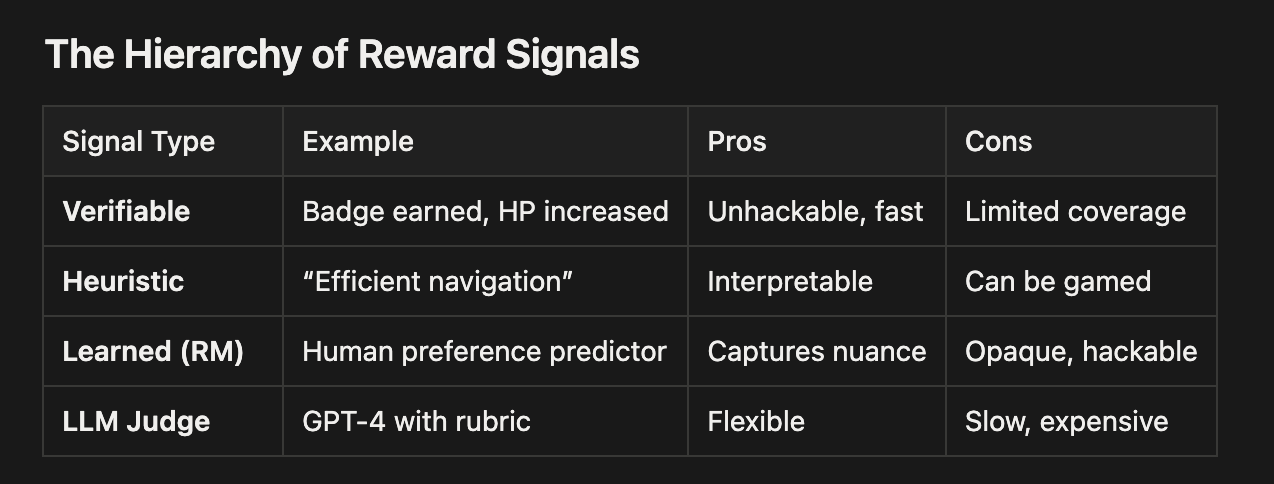
From Anthropic’s Guide to RL and Reward on Pokemon Red. As domains grow unverifiable, and SOTA data to hillclimb becomes ever more long horizon, non-domain experts shouldn’t at all be allowed in reward shaping.
The classes of verification problems I mentioned before are what create the delineation between Type 1 and Type 2 data. Domains where relevant white collar work are harder to verify naturally require more Type 1 data to do work on. Important to note - I do not condemn Type 2 entirely - it was a necessary place to start in 2024-2025 given state of AI model progress then. It is imperative, though, that current human data companies significantly invest in continual efforts to shift Type 2 to “Type 1.5” intermediates. This often manifests in efforts like:
Working extremely closely with a small group of domain experts who are almost treated like employees at a personal level, who are also taught some amount of good reward shaping methods from an MLE perspective as to reduce expertise dropoff as much as possible
Creative incentives in humans for human-based QA - if you create data for long horizon RL, you should also expect reward hacking in long horizon RL data. Humans, even more so than models, are the most preeminent experts in reward hacking, especially when they’re paid $20/hr
QA from internal teams layer by layer. Inefficient, but when the ops teams QA the contributors, and the MLEs QA the ops teams, and the final sale is QA’ed by everyone, you can add another inefficient layer of QA.
But this is not a commentary espousing Type 1 data’s direct superiority over Type 2. Just like oil grades for cars - whereas some cars require 93 grade while others 87, Type 1 is more abundant and useful for getting models from “0 to 20” while, at a certain point of model sophistication, Type 1 is necessary for getting “20 to 80.” They have different use cases and are valuable at different stages of model training. Important to note - Type 1 and Type 2 data are separate from pre-training and post-training datasets. It is possible to create contrived data for pre-training modalities that sees operational quality issues related to production, and entirely impossible to bill Type 2 data as Type 1 data when there is actually a great deal of reward shaping from non-domain experts.

In general, we still lack data production relative to the amount of willing spend. Models and data power AI model progression, and we generally lack data moreso than compute (which will change as models get better, obligated Jevon’s Paradox citation). Type 1 data will always be highly useful, but we need the operational speed and throughput behind good Type 2 data production for the highest velocity of model improvement for some modalities. For example:
“Multimodal data” like audio and video still require vast sums of pre-training like datasets in SOTA enterprises, making Type 2 data production optimized businesses like David AI remain consistently useful.
Opus 4.5 consistently oneshots most coding tasks that adherents in Type 2 data production will produce, making Type 1 task observation and then mimicking in an RL-actionable format almost the only way to define economically valuable tasks to hillclimb on
A mixture of both is necessary to match the SOTA pre and post training process for models; in a simplistic fashion, you can imagine Type 2 data acquisition processes valuable when pre-training is still prevalent, and Type 1 more valuable when sophisticated post-training is the only way to hillclimb on economically valuable use cases
The issues today mainly lie in the fact that type 1 and type 2 data are often obfuscated and human data companies that largely scale type 2 data do so with many operational failures (stemming to a mixture of cultural issues). Common issues include:
Large human data scaler companies create evals that represent unrealistic data/tasks, then subsequently supply data at large scale to hillclimb on those evals. This creates a perverse incentive where, for example, if a SOTA model already performs well out of the box on evals, tasks within the eval will be made more difficult to give an illusion that there is still a lot of hillclimbing to be done. This works especially in domains where researchers/human data procurers are not domain experts themselves.
QA work is largely seen as an operational job, whereas it should be an engineering one (and most jobs within data companies, by extension). Engineering teams should spend as little time as possible in one off forward deployed sales bakeoffs, and as much time building automated QA pipelines, env generation, and the whole host of Antikythera mechanisms to be built.
Type 2 data is largely billed as type 1 data; eg every human data company will espouse that they have the “best data” while this is intrinsically impossible because of how they use their contractorsAnd researchers, sometimes being unsophisticated about this, ask for large quantities of Type 1 data that vendors interpret, misconstrue, and pitch as Type 2 data. Though labs may attempt to standardize data collection, implementing human data teams within labs creates communication friction between human data teams and researchers themselves that make it harder to communicate with vendors. This is a large decision factor behind many labs keeping data acquisition budgets in the hands of researchers as well.

Model improvement velocity is a function of compute, data, and talent investments by labs. A lack of any of the three results in overcompensation by other domains to make up for it (eg Flapping Airplanes’ focus on data efficient algorithms, or overzealous use of synthetic data for out of distribution use cases). We introduce a crude imbalance penalty to model this.
If you’re interested in getting appraised in our private evals on Type 1/Type 2 data and working with us on improving/implementing data collection methods as to optimize for Type 1/2 data production, feel free to contact me.
Hillclimbing Models (or convincing people that your data can hillclimb)
Tasks in envs need to be just slightly harder than SOTA model capabilities but within reach. It is probably hard to start automating the work of radiologists, but much more within reach to automate the work of mid-level software engineers:
At a more technical level, a long horizon RL rubric that gets real buyer interest is not one that merely produces low pass@1 numbers. Difficulty, in isolation, is cheap. You can always write an eval that frontier models fail and people need to separate the fact that buyers are not purchasing failure rates, they are purchasing hillclimbness which is the property that a model can be pushed upward on the distribution with a plausible amount of post-training compute and the right data. GPQA was valuable in 2023 because it embodied an older paradigm of difficulty that was still cleanly verifiable. It was hard, but correctness was objective, errors were localized, and expert oversight was mostly a question of whether non-experts could validate the answer or not. But once you move into long horizon environments, the object of optimization is an entire trajectory of tool calls, intermediate reasoning steps, and recovery behaviors.
In these regimes, pass@1 ceases to be a measure of “can the model solve the task,” and becomes a measure of “can the model one-shot the entire workflow correctly, without drifting,” which is drastically more difficult. Long horizon tasks are mechanically long as episodes span hundreds of actions, tools are non-deterministic, intermediate subgoals are ambiguous, and a single error early in the rollout ruins the entire attempt. If your environment is unstable, your evaluation is unstable, and if your evaluation is unstable, your training loop collapses into variance. Pass@k becomes more informative here not because we care about sampling tricks, but because it reveals whether success is reachable at all under modest exploration. If pass@1 is 0% but pass@30 is 30%, you have something hill-climbable. If pass@1 is 0% and pass@200 is still 0%, you have built a benchmark, not a training target.
Rubric construction is paramount, and a single long horizon task can almost become its own product and environment. Functionally, you want tasks that are just beyond the current policy frontier, but still structurally learnable; these are environments where reward can be shaped without being gamed, where tool calls are deterministic enough to permit reproducible rollouts, where task coverage is economically meaningful rather than contrived, and where the complexity comes from real workflow depth rather than artificial obstruction. The novelty that matters is not novelty in the benchmark sense, but novelty in the sense of capturing a slice of white collar work that is still unautomated precisely because it is non-verifiable. The best envs therefore look less like GPQA-style question sets and more like minimally invasive encodings of professional process, where the rubric is grounded in what experts actually do, and where the difficulty is not fabricated but emergent from the irreducible length and ambiguity of the task itself.
Functionally, once you decompose something like a front end engineering workflow into 200 sequential tool-mediated steps, you have effectively defined an RL environment in the same way GPQA defined an evaluation distribution: it becomes its own closed benchmark of competence, with its own action space, failure modes, and rubric-shaped notion of correctness. The task is no longer “build a Ramp UI,” it is “navigate this particular trajectory manifold without drifting,” which is why long-horizon workflows start to look less like single problems and more like self-contained worlds that models must learn to operate inside.
I think this is a broadly correct way to think about it, and it is how serious labs increasingly operationalize these domains internally. The only caveat is that it can be slightly misleading if you treat the environment as an abstraction rather than a fidelity constraint because the moment the 200-step decomposition becomes contrived or overly scaffolded, you are no longer measuring front end engineering, you are measuring your env design. The best long-horizon benchmarks are almost indistinguishable from real workflow capture and the worst are just puzzles dressed up as work.
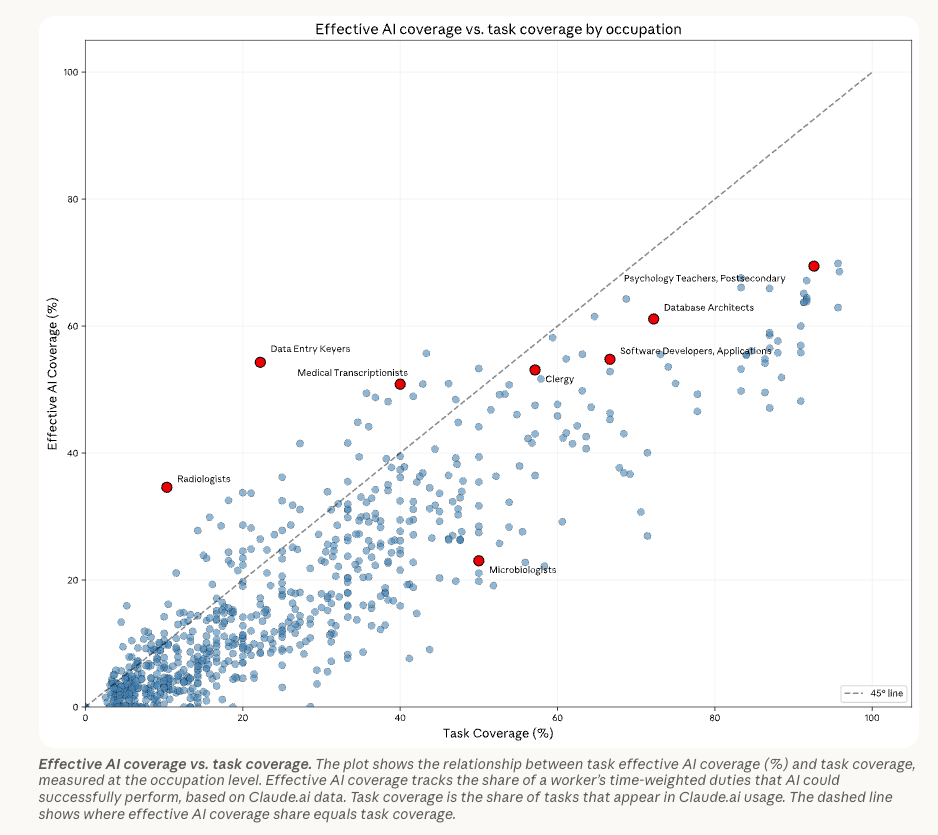
Anthropic is the lab that is most acutely aware of the problems regarding data sales I cover above because of their enterprise first focus and general disregard for “hot benchmarks.” This is well placed; by focusing on enterprise first you will become extremely opinionated about the sort of data that best hillclimbs models and subsequently, by first principles, discover that most of the hot benchmarks like Mercor’s APEX and OAI GDPEval are not actually realistic. This is why, Anthropic is the lab most known for driving towards exclusivity when a novel env format is found, but otherwise a procurer of “raw data.”

Anthropic’s economic report is a useful, interesting barometer of app layer sophistication. This draws even more fuel to the argument that coding/search were the most mature app layer categories.
Convincing people that your models can hillclimb can be done in many different ways:
You can set new research standards for addressing interesting nuances in non-verifiable white collar work tasks -e.g. the fact that front end design is still not solved at a step by step front end low level design choice workflow stage and more at a pure HTML/CSS replication copy stage leaves a lot of room of innovation there
Training models on your own data to prove its good (aka internal post-training to test data quality before delivery). This can combat perceived QA deficiencies in heavy human QA-driven processes in Type 2 oriented processes, as well as make Type 1 datasets premium
A recent engagement between Applied Compute and Mercor is an example, although this focuses more on robust data to hillclimb models in absence of abundance (overcoming data scarcity in producing model gains).Extremely robust envs that are regularly resupplied with real world data. Real world data pipelines —> automatic conversion to new data for RL envs and few sparing tool calls/additions is what this would look like
This is especially effective for white collar domains that don’t have too much changing verification veracity and too many best practices changes such as to mandate rapid bespoke tool addition/subtraction from envsData lineage and pitching “robust human QA” pipelines. This is providing “audit-like” reports of where your data actually comes from, how it is sourced, how QA is done (and mitigating the worst of human-guided QA bias), as a measure of quality for datasets.
That this is so often today misrepresented in white collar domains implies that researchers should be more wary of data lineage.
You should also be aware of how truly sophisticated your customer class is. For some researchers who mostly treat data spend as “research projects” (notably concentrated in OAI in Jan 2026) because a large variety of research directions are funded, vendors can find a “teach your customer” motion is more viable. Subsequently, researchers who are extremely focused may ask for white collar reasoning trace data at the most raw, highest fidelity form (almost session replay like with context over individual keystrokes) along with some sort of high trust intention labeling over it.
As of Jan 2026, it is undeniable that many of the top labs have shifted preferences to procuring raw data as to expecting their vendors to be thought partners and direct RL env providers, owing to the enduring poor quality of envs from newer vendors. Good QA for unverifiable domains, and increasingly complex long horizon RL, is extremely short supply. Domain specific vendors in hot AI spend categories who will have internalized information from the RL Env Field Guide as well as harboring MLE teams who can post-train models on their own data (in addition to well built QA pipelines from engineers with both domain expertise and RL talent) will inspire the most confidence in researchers.
I mentioned earlier how shifting a real world workflow like a 200 step long horizon RL task for, say, a front end engineering task of replicating Ramp, is almost like an env itself.
Interestingly, if you were to build this task via as faithful Type 1 data production as possible, you would call it “raw data,” perhaps with a few pipelines for conversion into a model actionable format. But if you were to build it with contrived Type 2 means, it would be an “RL Environment.” While it is true that construction of this long horizon task would require making tool calls for a trialer model that are static, deterministic representations of real world equivalents in both Type 1 and 2 data, Labs’ shift to procuring raw data implies a preference for Type 1 data.
Perhaps it is telling that some of the env companies today that have had no trouble immediately securing contracts are those that are recent ex-researchers themselves. In general, much of the AI infra services category (human data and RLaaS) can be described as “MLE talent arbitrage.”

Feel free to share this image, if anything, from this article.
My next article explores how and why contrived data, even as described in this article, is twisted beyond realism in human data companies’ charge to produce high volume data, as well as exploring the investment efficiency mechanics in the bottom of the above chart. Specifically, m, and q are extremely telling reflecting indicators of AI app layer companies (Rogo, Harvey, Decagon) and commentary on how 95% of the US economy remains separated from the benefits of AI investment.
The full article will release on substack later this week. I’d love to talk to you if you’re a frontier lab researcher or founder in the space. Data quality and unrealistic QA shouldn’t bottleneck work on the next generation of scaling algorithms.